第一个 Lab,使用 xv6 提供的 Sys Call 写一些工具。
最近开始了 6.S081 之旅。
这个课公开的有 2020 版的录像和实验,以及 2021 的实验,2022 课程编号变成 6.1810 其实还是同一门课,只是有了正式的课程编号。
他是 6.828 这个经典的操作系统课程的改版,其中最大的变化是 xv6 基于 RISC-V 重写,以适应 6.004 的教学。以及 Lab 重新编排。
我是个菜鸡,因此尽管比对了 2021 的 Lab 与 2020 变化不大,我还是选择了 2020 的课程来做。
鸡你太美(不是
Tools
我原本打算在 macOS 上直接运行,但不知道为什么使用 macOS 装的最新版的 Qemu 进不了 xv6,他根本不引导,因此我的实验环境放在了 Linux 里。
为避免过于新版本的问题,我选择了 Debian 11 作为实验环境,安装了 LXDE 作为桌面环境。
按照 Tools 页面的指引安装就可以了。
评分脚本是 Python 的。而且因为他使用了 python 命令而非 python3 我严重怀疑他是 Python 2 写的,因此安装 Python 2 就好。
1sudo apt install python2 python-is-python2
Util Lab
课程的第一个 Lab,让你使用 xv6 提供的 Sys Call 实现一些小工具。
Boot xv6
只是启动 xv6 环境的教学,略过。
sleep
简单上手一下 C 语言和 Sys Call。写一个简单的 Sleep 程序。
教授的代码风格是传统 C 风格,我也就入乡随俗的去写了。
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4
5int
6main(int argc, char *argv[])
7{
8
9 if (argc == 2)
10 {
11 sleep(atoi(argv[1]));
12 exit(0);
13 } else {
14 fprintf(2, "Usage: sleep [ticks]\n");
15 exit(1);
16 }
17}
这里只是涉及了如何处理参数,如何调用 Sys Call 等简单问题,只是一个简单的热身罢了。
pingpong
涉及到管道,以及多进程编程等。
当使用 fork() Sys Call 的时候,程序会将当前状态完全复制,包括内存,文件描述符等,两部分一起运行。
根据操作系统实际的处理方式不同,这些复制的内存(肯定是复制了虚拟内存的页表啊,还用想吗)在物理内存中可能是指向相同的位置,应用写时复制的特性以优化性能,也可能是在 fork 的时候复制。xv6 默认采用了简单的那一种。
fork 后,主进程的 fork() 会返回子进程的 PID,子进程则固定返回 0。可以用这种方式来判断是主进程还是 fork 出来的子进程。
两进程的通信可以使用管道,管道是 Unix 提供的一种通信方式,管道一端输入的内容会从管道另一端出来。
xv6 的 pipe() 系统调用接收一个数组,数组的第一个元素是管道的读文件描述符,第二个元素是管道的写元素描述符。
主进程可以使用 wait() 系统调用来等待子进程结束。当执行到 wait() 时,主进程会阻塞,直到有一个子进程退出。
他接收一个 int 类型的指针,向该地址写入子进程的退出状态吗。
当不需要知道子进程的返回值时,可以传入 NULL。
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4
5int
6main(int argc, char *argv[]) {
7 int p[2];
8 if(pipe(p) == -1) {
9 fprintf(2, "Error when opening pipe");
10 exit(1);
11 }
12 char buf[1];
13 int pid = fork();
14 if(pid == 0) {
15 for(;;) {
16 if(read(p[0], buf, sizeof(buf))) {
17 fprintf(1, "%d: received ping\n", getpid());
18 }
19
20 write(p[1], (char*)'1', sizeof(buf));
21 exit(0);
22 }
23
24 } else {
25 write(p[1], (char*)'1', sizeof(buf));
26 wait(0);
27 for(;;) {
28 if(read(p[0], buf, sizeof(buf))) {
29 fprintf(1, "%d: received pong\n", getpid());
30 }
31 exit(0);
32 }
33 }
34}
primes
使用多进程编程实现一个质数程序,输入 35 以内的质数。
这个实现非常巧妙,让人不得不感叹前人的智慧。
实际上就是这一张图。
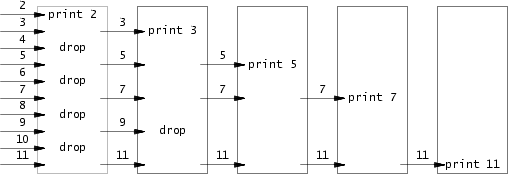
以及对应的伪代码
1p = get a number from left neighbor
2print p
3loop:
4 n = get a number from left neighbor
5 if (p does not divide n)
6 send n to right neighbor
这道题的难点在于,如何实现这么多子进程,以及 35 这个数字的限制实际来源于 xv6 系统的限制。由于文件描述符的上限很低,因此要及时关闭文件描述符。
对于一个 pipe,在进程 fork 之后实际上变成了 4 个文件描述符,即主进程的两个,以及子进程的两个。如果不及时关闭的话,文件描述符会很快达到最大限制。
管道里可以传送任何数据,包括 ASCII 文字,以及完全的二进制数据。
这是一个典型的递归程序。
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4#define MAX_PRIME 35
5
6void
7prime(int *p) {
8 // 不用的文件描述符及时关闭,例如此处不需要向管道中写数据,因此直接关闭写一端
9 close(p[1]);
10 // 从管道中读入第一个数,直接输出并记录
11 int primes;
12 if(read(p[0], &primes, sizeof(primes)) != sizeof(primes)) {
13 fprintf(2, "Error\n");
14 exit(1);
15 }
16 printf("prime %d\n", primes);
17 int left;
18 // 这里是递归边界,若管道为空,则 read() 会返回 0 代表没有读到任何数据
19 if(read(p[0], &left, sizeof(left))) {
20 int p1[2];
21 pipe(p1);
22 if(fork() == 0) {
23 // 对子进程,递归的对后面的数进行处理
24 prime(p1);
25 } else {
26 // 对主进程,关闭创建的新管道读一端
27 close(p1[0]);
28 // 从左侧管道读入数字,如果不能与头一个数整除,则送入右侧管道。
29 do {
30 if(left % primes != 0) {
31 write(p1[1], &left, sizeof(left));
32 }
33 }while(read(p[0], &left, sizeof(left)));
34 // 读写完毕后关闭管道
35 close(p1[1]);
36 // 等待子进程结束
37 wait(0);
38 }
39 }
40 close(p[0]);
41 exit(0);
42
43}
44
45int
46main() {
47 int p[2];
48 int status = 0;
49 pipe(p);
50 // 创建管道,将 2-35 全部送入管道,fork 出子进程传入管道,调用 prime 函数开始递归
51 if(fork() == 0) {
52 prime(p);
53 } else {
54 close(p[0]);
55 for(int i = 2;i <= MAX_PRIME;i++) {
56 if(write(p[1], &i, sizeof(i)) != sizeof(i)) {
57 fprintf(2, "Error\n");
58 exit(1);
59 }
60 }
61 close(p[1]);
62 wait(&status);
63 }
64 if(status) {
65 exit(0);
66 }
67 exit(1);
68}
find
一个非常不 Unix 的查找程序,之所以说不 Unix 是因为他只实现了基本的查找功能,而且命令用法和 Unix 的 find 命令也不一样。
和上一个程序一样,遇到文件直接比较文件名。遇到目录则递归查找。
其中 fmtname() 一开始是从 ls.c 抄过来的,因为这个还 Debug 了很久(
理论上这个程序可以改造成多进程版本,但我懒(
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "kernel/fs.h"
4#include "user/user.h"
5#include "kernel/fcntl.h"
6
7char*
8fmtname(char *path)
9{
10 static char buf[DIRSIZ+1];
11 char *p;
12
13 // Find first character after last slash.
14 for(p=path+strlen(path); p >= path && *p != '/'; p--)
15 ;
16 p++;
17
18 // Return blank-padded name.
19 if(strlen(p) >= DIRSIZ)
20 return p;
21 // +1 for '\0'
22 memmove(buf, p, strlen(p)+1);
23 return buf;
24}
25
26void
27find(char *path, char *filename) {
28 char buf[512], *p;
29 struct dirent de;
30 struct stat st;
31 int fd;
32
33 if((fd = open(path, O_RDONLY)) < 0) {
34 fprintf(2, "find: cannot open %s\n", path);
35 return;
36 }
37
38 if(fstat(fd, &st) < 0) {
39 fprintf(2, "find: cannot stat %s\n", path);
40 close(fd);
41 return;
42 }
43
44 switch (st.type) {
45 case T_FILE:
46 // 对于文件,可以直接比较文件名
47 if(strcmp(fmtname(path), filename) == 0) {
48 printf("%s\n", path);
49 }
50 break;
51 case T_DIR:
52 // 对于目录,则需要处理后递归查找
53 // 若路径太长超过最大路径大小,则直接崩掉
54 if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf) {
55 fprintf(2, "find: path too long\n");
56 break;
57 }
58 // 在路径后面加上 '/'
59 strcpy(buf, path);
60 p = buf + strlen(buf);
61 *p++ = '/';
62 while (read(fd, &de, sizeof(de)) == sizeof(de)) {
63 // 不要递归到当前目录和父目录
64 if(de.inum == 0 || (strcmp(de.name, ".") == 0) || (strcmp(de.name, "..") == 0)) {
65 continue;
66 }
67 // 把下级目录加进路径中并递归
68 memmove(p, de.name, DIRSIZ);
69 p[DIRSIZ] = 0;
70 find(buf, filename);
71 }
72 break;
73 }
74 close(fd);
75}
76
77int
78main(int argc, char *argv[]) {
79 if(argc < 3) {
80 fprintf(2, "Usage: find [path] [filename]\n");
81 exit(1);
82 }
83 find(argv[1], argv[2]);
84 exit(0);
85}
xargs
也处于基本能用的状态,有提到 -n 参数但并没有要求我实现,那就允许我偷个懒吧(不然我还得实现一套 getopt())
即便如此,这个实现最麻烦的是自己实现标准库中的 getchar() 和 gets()
既然要实现,索性实现了安全版本的 gets_s()
其实 gets_s() 是 MSVC 的实现,标准中只有 fgets(),但 fgets() 的第三个参数是文件流,索性从 MSVC 当中借过来这个名字算了。
1#include "kernel/types.h"
2#include "kernel/stat.h"
3#include "user/user.h"
4#include "kernel/param.h"
5#define NULL ((void *)(0))
6#define EOF (-1)
7
8int
9getchar() {
10 char buf;
11 if(read(0, &buf, sizeof(char))) {
12 return buf;
13 } else {
14 return EOF;
15 }
16}
17
18char *
19gets_s(char *s, int size) {
20 int c = getchar();
21 // 如果读到 EOF,则直接返回空指针
22 if(c == EOF) {
23 return NULL;
24 }
25
26 int i = 0;
27 do {
28 // 与正经的标准库函数不同,我们的实现由于根本不存在缓冲区,因此也不存在将 `\n' 继续留在缓冲区的说法,即下一次 getchar() 不会读到上一个 '\n'
29 // 这种实现更接近于算法比赛的快速读入
30 if(c == '\n') {
31 break;
32 }
33 s[i] = c;
34 // 如果达到最大大小,提前终止读入
35 i++;
36 if(i == size) {
37 break;
38 }
39 }while((c = getchar()) != EOF);
40 // 补上字符串的 '\0'
41 s[i] = 0;
42 return s;
43}
44
45int
46main(int argc, char *argv[]) {
47 int status, i;
48
49 if(argc < 2) {
50 fprintf(2, "Usage: xargs [command]\n");
51 exit(0);
52 }
53
54 // 缓冲区,用于 exec 的参数
55 char *buf[MAXARG+1];
56
57 // argv 是一个 char 类型的指针的数组
58 // 在运行时,argv 就已经确定,并且存储在 main() 的栈之前
59 // 直接拷贝指针的值避免了拷贝内存的开销
60 // argv 不保证连续,最好不要将 argv 作为一个整体内存去拷贝
61 for(i = 1;i < argc;i++) {
62 buf[i - 1] = argv[i];
63 }
64
65 // buf2 作为读缓冲区使用
66 char buf2[1024];
67 int args = argc - 1;
68 while((gets_s(buf2, 1024)) != NULL) {
69 int j = 0;
70 int l = 0;
71 // 处理掉可能存在的前导空格
72 for(l = j; buf2[l] == ' ';l++) {
73 ;
74 }
75 j = l;
76
77 for(int k = j; ;k++) {
78 // 再次处理空格分割
79 if(buf2[k] == '\0' || buf2[k] == ' ') {
80 char *s1 = malloc((k-j+1)*sizeof(char));
81 memcpy(s1, buf2 + j, k - j);
82 s1[k - j + 1] = '\0';
83 buf[args++] = s1;
84 if(args == MAXARG - 1) {
85 fprintf(2, "xargs: Too many arguments...\n");
86 exit(1);
87 }
88 for(; buf2[k] != 0 || buf2[k] == ' ';k++) {
89 ;
90 }
91 j = k;
92 }
93 if(buf2[k] == '\0') {
94 break;
95 }
96 }
97 }
98
99 // argv 以 NULL 或者说 0 作为结束标志
100 buf[args] = 0;
101
102 // fork 一个子进程执行命令,主进程等待子进程执行完毕
103 if(fork() == 0) {
104 exec(buf[0], buf);
105 } else {
106 wait(&status);
107 if(status == 0) {
108 exit(0);
109 } else {
110 exit(1);
111 }
112 }
113 exit(0);
114}
115
116可选的挑战也许我会找时间补上。
评论